Doing SEO in Shopify is like doing SEO in hard mode.
A hosted CMS prevents customisation when need be. Robots.txt is locked in. Sitemaps are automatically generated. Content types are 'locked in' and liquid is a limited templating language that makes referencing related content harder than it needs to be.
When you Google 'Is Shopify Bad for SEO' the top result is me whinging on Quora about its shortcomings. Optimising crawl for a complex Shopify website with a structured hierarchy of information is definitely challenging, and the limitations can make you feel powerless at times.
All isn't lost - as long as you understand your goals and the limitations of Shopify then you can work within those limits to emulate 'good' SEO for a large, complex website then you can achieve your SEO goals for the project.
I learned this the hard way over the past four years working on Kiana Beauty - a website whose IA was designed for Magento but built in Shopify.
A little history on how Kiana Beauty was designed
Kiana Beauty is the online arm of Berwick Pharmacy that launched in January 2015 after a difficult development period. The process started sometime in 2013 when a web development agency was hired to build the original vision of Kiana Beauty. The website was originally built on Magento, however, the agency hired failed to capture the requirements as listed by my employer.
Fortunately, Shen and his fine team at Mod Media were able to rescue the project and, in the process, migrated the Kiana Beauty website to its new platform -Shopify.
On launch, the Kiana Beauty website had some interesting features that worked well within the limitations of Shopify. Namely, the sidebar filtering menu was a mechanism used within Shopify's core functionality to narrow a collection based on tags.
This created some interesting twists on how to work around Shopify's limitations to create a faceted navigation within Shopify by using the / mechanism for collections.
This would alter collection URLs like the following:
/collections/chanel➔ The root collection/collections/chanel/oily-skin➔ The collection filtered for all products formulated for Oily Skin/collections/chanel/oily-skin+skincare➔ The collection filtered for oily skincare products. Non-indexable.
Since launch, these faceted navigation items have lived by the sidebar of these collections throughout the website. Whilst great from an IA standpoint, they also add a challenge of introducing numerous URLs on the page that will exhaust crawl budget!

Customising Shopify's Faceted Tags for Longtail SEO
Crawl optimisation was the lower end of priority as by 2016, our crawl rate was only ~1500/day.
Instead, my original focus was to use our specific information architecture to optimise for the following:
- Page Title: Manipulating the
<title>content to best fit the faceted collection results page. - Description and Meta Description: Changing the meta description so that it is differentiated between URLs within context.
- Structured Data: As the objects of each collection are fieldable, adding the structured data for the Collection Pages were also a high priority. Since we were doing the title logic anyway, it was useful to do it as well.
Tags are treated as term references within Shopify's admin - they do not exist as objects on their own. They must belong to a product in order to exist, which creates a few issues.
- Discrepancies with Tags Syntax: All tags when computed become 'handleized', converting all spaces and stopgap characters into hyphens. There are issues with manual input with formatting with the UI, with mismatched tags in input conflicting. Using tools like Bulk Edit Tags by Power Tools help consolidate this and prevent bugs and conflicts.
- Tags in Shopify ALWAYS return a 200 response: There is no mechanism in Shopify for 0 results to return a 404 response. Instead, a 200 response is always returned. This adds risks in broken links linking to dead pages but adds advantages of vanity urls using the tag notation i.e.
/collection/chanel/afterpay - Tags greater than 1 level deep are non-indexable: Shopify has a locked in
robots.txtfile. As a result, all URLs with a+in the URL are not directed to be indexed.
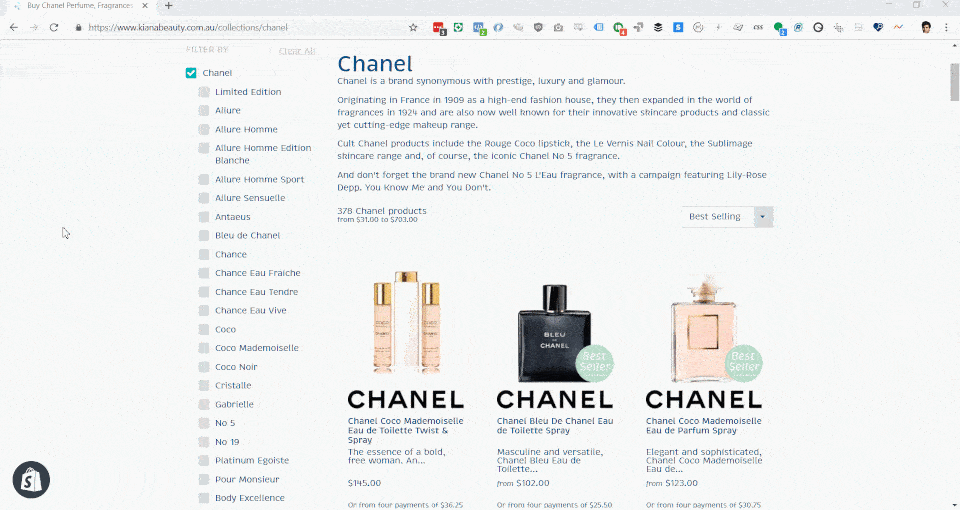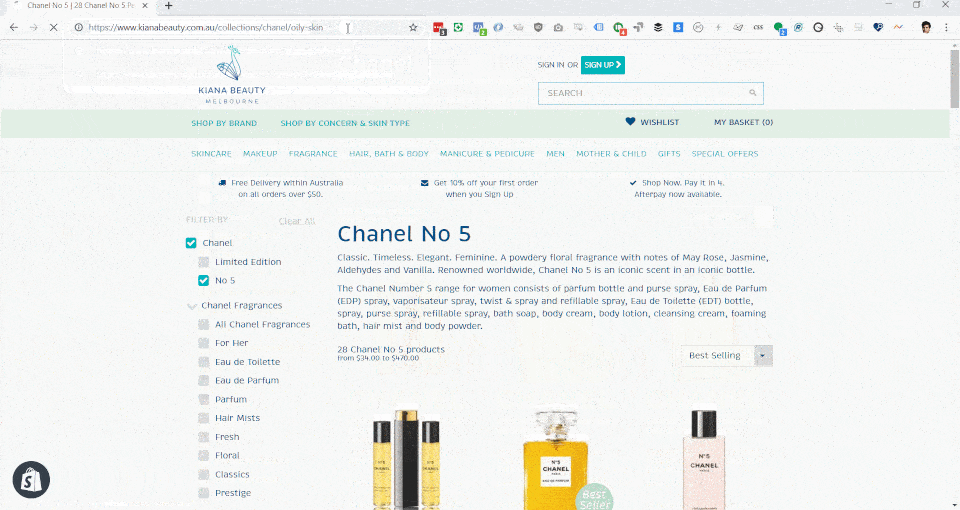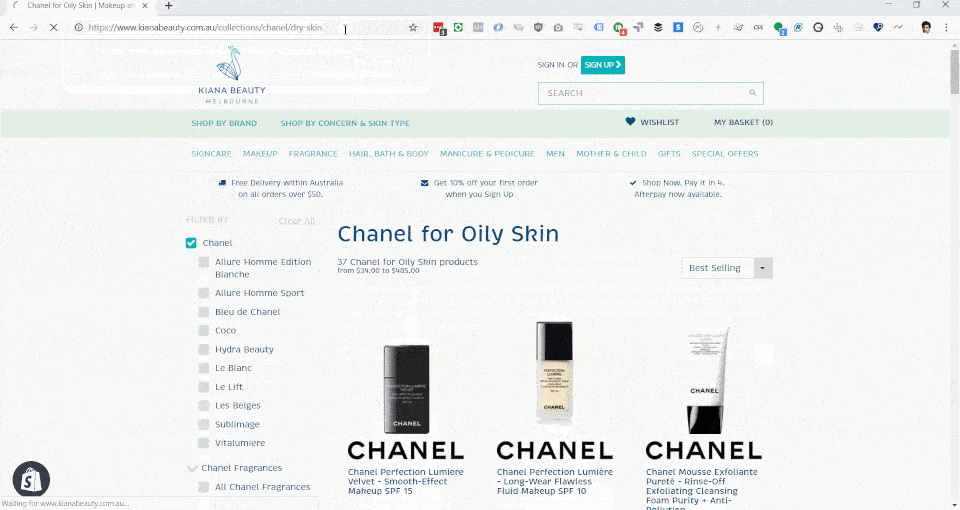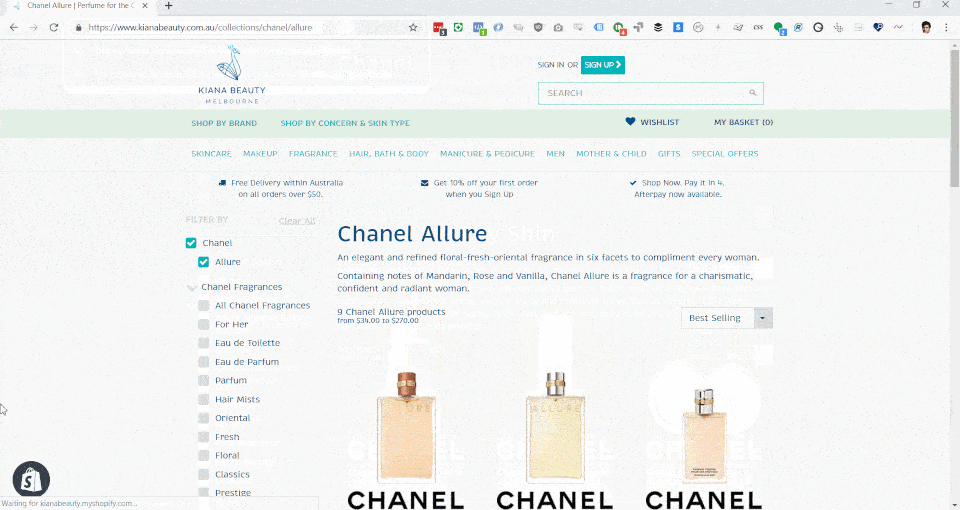
Using some workarounds with Shopify's link lists, handle matching with non-public pages, we were able to create a sophisticated and world-first method of controlling the content of page titles, page descriptions, number of products and price ranges for faceted collection results page.
As there are over 100 collections, including individual brands, and over 100 filters that could potentially be applied to that collection, the number of crawlable links that need to be optimised for page relevance was numerous and overwhelming.
This switches from an SEO decision process to a business decision process, in which manual overrides were preferred for high performing brands revenue-wise (i.e. Chanel), new ranges which are more open to competitive SEO and exclusive ranges with little competition.
That said, I wanted to have customised, contextual content for as many pages as possible - including these faceted pages.
So, I included logic within the code the render <title>, <h1> and the <meta name="description"> to be cascading - no matter what the scenario, some page title would render. The closer to manual adjustment, the more accurate and contextually relevant that page title is.
The cascade order is as follows, from highest to lowest:
-
(1) Manual Handle Match: A collection of page would match the collection name + handle in order to produce manually written content. This hidden piece of content is non-discoverable for indexing and exists just as an object reference for content. Example:
/collections/chanel-coco-mademoisellewill become split, reading the first part of the handle to see if it matches an existing collection (/collection/chanel) and the rest of the handle (-coco-mademoiselle) is trimmed, cleaned up and combines to retrieve the destination URL of/collections/chanel/coco-mademoiselle- Example: Chanel No 5
/collections/chanel/no-5/ - Example: Chanel Coco Mademoiselle
/collections/chanel/coco-mademoiselle - Example: Yves Saint Laurent Black Opium
collections/yves-saint-laurent/black-opium
- Example: Chanel No 5
-
(2) Smart Default: Smart defaults use Pattern matching for the tag itself, and applies it in a default pattern, replacing the collection name with the mutable part of the title. Example: Waterproof {{ products}}, {{ products}} for Oily Skin, Travel-size {{ products}}. Risks: Incorrectly rendered sentences, double use of text (i.e.
Makeup Makeup Removers, so utilise theuniqstring filter in Shopify.)- Example: Travel-size Chanel
/collections/chanel/travel-sizeTravel-size Skincare/collections/skincare/travel-size - Example:Clinique Foundations
/collections/clinique/foundationsThin Lizzy Makeup Foundations/collections/thin-lizzy/foundations
- Example: Travel-size Chanel
- (3) Pattern Default: The default setting. The
<h1>is untouched, with only the<titleamended to include a- tagged {{ tag name}}in the title. Usually reserved for tags I haven't gotten around to, or possible conflicts. (i.e.tonershas no Smart Deaults, as one is created fortoners-and-mists). - Hard Default: Ideally will not trigger, but the
{ else}statement that renders a hard default of the collection default. Also trigger for non-indexable tags, such as 2+ levels deep - i.e. anything with a+in the URL.

Optimising Crawl Budget
In 2019, our daily crawl budget is ~3.5k-4k a day, meaning that crawl optimisation has risen to become a priority.
As mentioned earlier, Shopify has a locked robots.txt file which makes identifying the first casualties of our crawl optimisation process easy - non-indexable pages.

For our faceted collection results pages, crawl optimisation targets are pretty simple - any URL with a + in it.
I could also choose Pattern Default URLs as a target, but there is a clear history of organic traffic being driven so I decided to leave them in the index for eventual consolidation.
The process is quite simple, include the following code in Shopify for the rendered anchor text.
{% if link.url contains '+'}{% assign link.url = link.url | replace:'<a href', '<a rel='nofollow' href'}{% endif %}
The above is pseudo code, it actually is a little trickier depending on how deep nesting was in a for loop but fundamentally you are doing two things:
- Check if the URL has a
+ - If it has a
+, replace the<a>text withrel="nofollow
Simple. I also had to apply nofollows for redundant pages in the blog section, mobile menus and other instances.
However, crawl optimisation where you can't remove URLs is best handled with a nofollow. This prevents the spider from wasting precious resources into following a URL with no commercial SEO benefit.
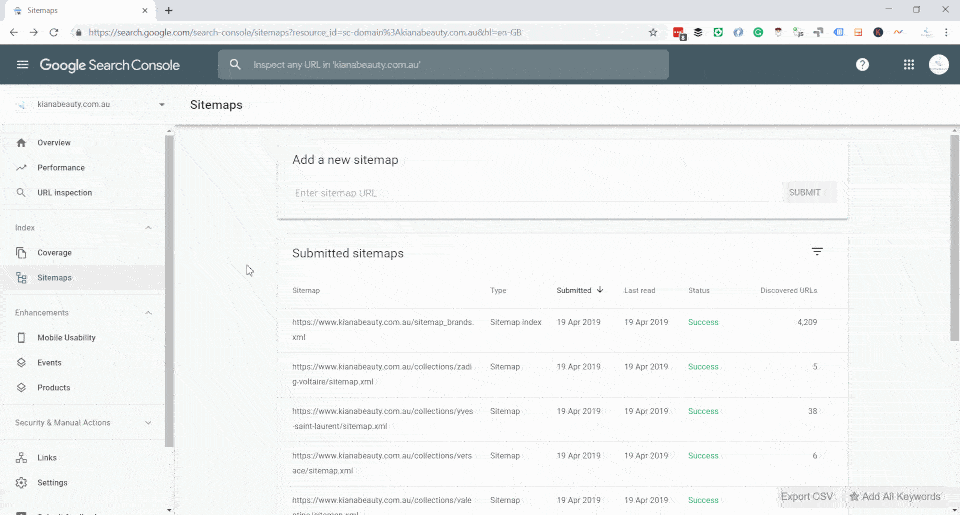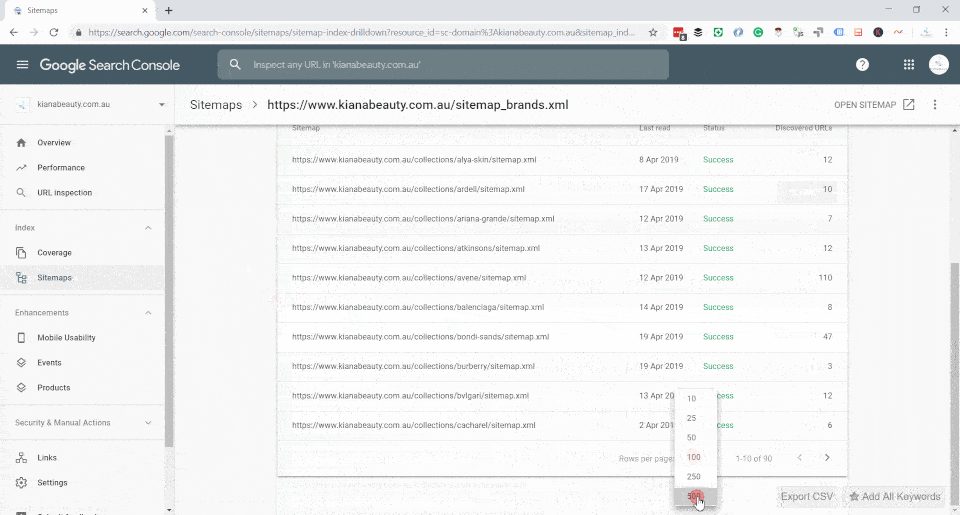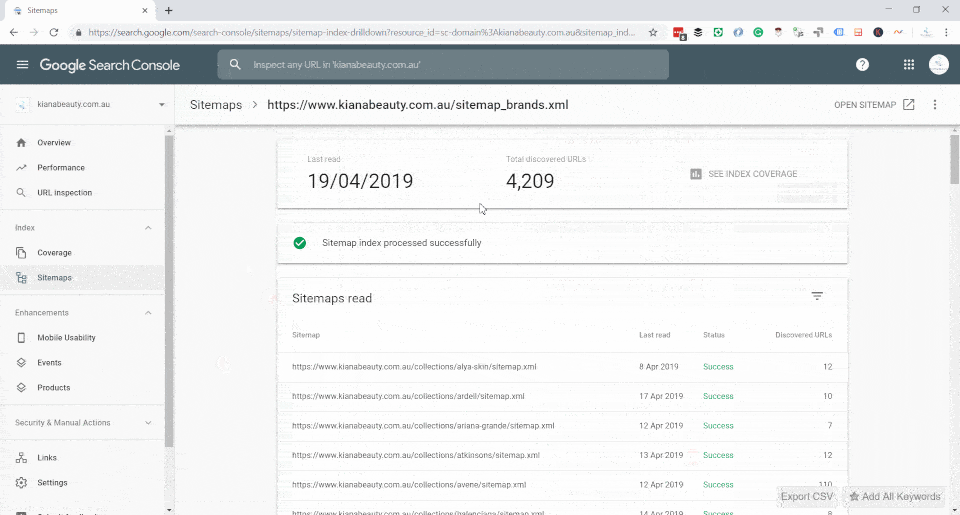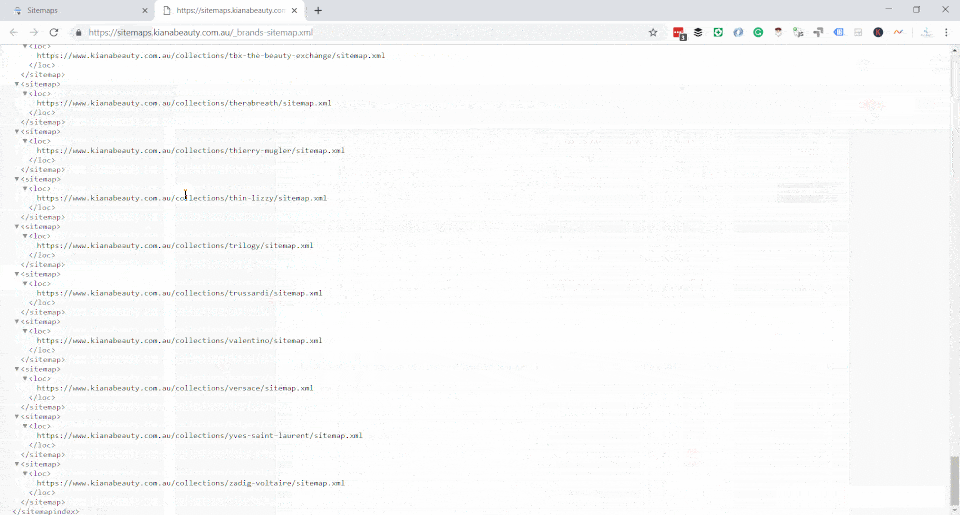
Customising Sitemaps in Shopify
With the negative aspect of crawl optimisation out of the way, we now get to the exciting part - proactive way to increase and dictate crawlability.
There are many creative ways of doing this from pinging URLs, URL Inspection in Search Console (née Fetch and Rendering), building links but the most stable way to increase and control crawlability on scale is via the sitemap mechanism.
Shopify handles sitemaps in an unusual way - it is a hosted platform, so the user has no control over the /sitemap.xml location. Shopify breaks up the sitemap in four different categories:
- Products: An automatically generated sitemap of products in which lists each and every eligible, published product on the website. All products are listed by the default system set canonical URL which is formatted as
/products/product-name. This sitemap is named as/sitemap_products_1.xml?from=[lower-product-id]&to=[highest-product-id]and is queried as a result. - Pages: An automatic listing of all
pagesin the Shopify store. Pages are a utility content type with no real structure behind it and are useful to fit custom content, or the create utility functions within liquid. - Collections: An automatic listing of ALL collections, including those automatically generated by Shopify that have not been excluded.
- Blogs: Shopify has weird naming conventions. A 'blog' is more like a blog category, as a single store can have multiple 'blogs'. This contains both 'blogs' (read: categories) and articles - which used to be entirely slug based and have non-editable URLs (fortunately, those days are behind us).

How to omit utility resources from Shopify's Sitemap by using metafields
Out-of-the-box, it isn't obvious how to control the output of the sitemap. Kiana Beauty has 3-4k worth of pages that would be included in the automatic sitemap by default.
However, our website is heavily customised to emulate a more structured CMS and as a result - many pages and collections are merely utility items and are never supposed to be public facing.
So, how do you hide products, collections, pages and 'blogs' that exist as little pockets of data and are not fated to see the light of day?
Shopify has a mechanism buried in their docs on how to hide a resource from sitemaps. This isn't exactly the easiest thing in the world to find, fortunately I have a pavlovian response to look up Jason Bowman's blog to work out a weird Shopify Metafield trick.
In order to hide a page, product, collection or blog from the sitemap you will need to add the following metafield key:
"namespace": "seo""key": "hidden""value": 1"value_type": "integer"
This is basically a boolean statement, setting the property of hidden in the namespace seo to true, which would hide it. It seems a bit hacky, since it is an integer input, not a boolean and that setting something to true makes it in reality false, but you work in what you are given with hosted platforms.
Metafields are neat, but a bit weird. They are additional data associated with an object that can be referenced in code. They can also be referenced by Shopify itself for some core functions, such as <title> and <meta name="description"> which are both global metafields attached to an object. Accessing these are tricky, and for the longest time, you had to use an App or use Jason's tool ShopifyFD to add metafields.
Unfortunately, due to recent changes in the past year with Shopify's new admin ShopifyFD is a broken tool with no immediate fix date. This is particularly tough, as the half working tool doesn't work on collections - which is where our subcategory logic did most of its grunt work.
To make due, you have to use the bulk edit capabilities within Shopify, which are available as follows:
- Collections:
https://example.myshopify.com/admin/bulk?resource_name=Collection&edit=metafields.seo.hidden&limit=1000&order=desc - Products:
https://example.myshopify.com/admin/bulk?resource_name=Product&edit=metafields.seo.hidden&limit=1000&order=asc - Page:
https://example.myshopify.com/admin/bulk?resource_name=Page&limit=1000&order=desc&edit=metafields.seo.hidden%3Astring%2Chandle&show=&ids=&metafield_titles=&metafield_options= - Article:
https://example.myshopify.com/admin/bulk?resource_name=Article&limit=1000&order=desc&edit=metafields.seo.hidden%3Astring%2Chandle&show=&ids=&metafield_titles=&metafield_options=

How to Add Custom Sitemaps in Shopify using to 301 Redirect Trick
With the one-to-one mapping involved with hiding object from sitemaps not exactly the most scalable method, how does Shopify handle adding new content to sitemaps on scale?
Unfortunately, there is no native method of adding pages in the sitemap that do not exist as part of the predefined allowed objects. No tag pages. No search pages. No special ?view= exceptions.
Additionally, Shopify do not allow you to control the HTTP Headers of a page directly on the theme level - so whilst you can create your own custom sitemap page using the ?view= template, the header will still respond as HTML and will not validate on submission.

Fortunately, Google Search Console has a variety of techniques that allow for the submission of sitemaps without access to the front-end of the website. One technique is using a 301 Redirect trick in Google Search Console from a non-existent file to a valid sitemap hosted externally.
This is harder than it should be in Shopify - it is very tough to find a 404 page within the Shopify, as with things like invalid paths may return 200 if they belong to a valid parent (i.e. collection/broken-url-that-returns-200-response).
The easiest way to generate a 404 and keep some kind of predictable URL structure is to redirect an invalid file (i.e. .xml) to a valid xml file hosted elsewhere, such as a subdomain.
For Kiana Beauty, I had converted /collections/collection-name/sitemap.xml (which doesn't exist and 404s) and I redirected it to a valid version on sitemaps.kianabeauty.com.au/collectionname-sitemap.xml and submit it via Search Console.
Interesting Fact: You don't have to do it this way anymore with the redirect. You could just reference the file directly using the domain view in search console. So a sitemap on sitemap.example.com/sitemap.xml with URLs pointing to the parent domain totally works now. Much easier solution, as you can create an app or even a different CMS whose purpose is just to be the missing sitemap.
As a result, we now have the missing URLs discoverable in our sitemap for pages like Tags that exist in our collection, we want to exist in Google since they are 55% of our organic traffic but can't be added natively to the default sitemap in Shopify.
The way we currently implement is manual, which is a pain. The HTML version of the sitemap output exists on ?view=sitemap, but I still have to copy and paste that content into the individual _sitemap.xml files on sitmap.kianabeauty.com.au which is not ideal.
We do have hosting for the subdomain, so I could write a script or even use something like Drupal as a CMS just to manage the sitemap source and outputs so that it is 100% automatic using cron jobs but that will be a task for another day.
Reflecting on doing SEO for a large, complicated Shopify store
So we can see that doing SEO and Information Architecture design on scale for a big and complicated store can be hard and burdensome.
But it is definitely doable. You just have to put the work in, know the pitfalls and work within the limitations of Shopify.
2019 is an exciting time and as the whole Headless CMS space gets more interesting, we can probably see more Shopify stores being built on something like Gatsby for the front-end to solve the issues that exist with the hosted platform.
But if you are building a complicated Shopify store and are using the liquid rendered front end, the steps you can work with are:
- Use handle matching with hidden pages to control the content of tags: Using a clever pattern on the handle of pages to match the handle of indexable tags can allow you to use these pages as an object to store the
<title>,<meta name="description">,<h1>andContentof that tag page. - Use a
nofollowon non-indexable links to save crawl budget: Shopify has a lot of non-indexable pages thanks to their fixedrobots.txt. Skip the headache, save your crawl budget and nofollow those links. - Omit webpages from Shopify's Sitemaps using metafields: Use the hidden
SEOmetafield, setting it to1for pages, collections and products that are not meant to be indexed. I also have logic that if a template containsnoindex, then a noindex will appear in the<head>. A word of warning: you cannot removecanonicalfrom Shopify, even if you have anoindex.noindexandcanonicalshould never be on the same page, but Shopify's devs don't know this. - Use a custom sitemap hosted externally for indexable pages that don't exist in Shopify's sitemap: Content such as formated tags, weird little hack and other pages excluded from Shopify's native sitemap feature can be included with your own custom sitemap. Crack open the code editor and get to work.